데이터프레임 생성
우리의 목표는 데이터를 최대한 예쁘게 만드는 것이고, 그게 우리가 해야 할 작업이다. 이는 데이터 분석 작업에서 60% 정도를 차지할 정도로 중요하고, 또 많이 익숙해져야 하는 부분이다. '이거 해주세요' 하면 '네'하고 바로 할 수 있을 만큼. 의사가 수술할 때 어리버리 떨지 않는다. 그만큼 익숙해져야 한다. 뭘 해야할 지를 알고, 착착 수술해나가는 것이다.
데이터프레임이란?
Pandas 사용 목적은 데이터프레임을 사용하기 위한 목적이다. 왜냐? 데이터를 처리, 조회, 분석하는 가장 효율적인 방법이 데이터프레임을 사용하는 것이다. 직접 만들 수도 있지만, 보통은 csv 파일, 엑셀 파일, 또는 DB에서 읽어온다.
데이터프레임 직접 만들기
pd.DataFrame() 함수를 사용해 데이터프레임을 직접 만들 수 있으며, 리스트, 딕셔너리, Numpy 배열 등을 활용할 수 있다. 머신러닝 모델의 성능 정보 등을 데이터프레임 형태로 분석해야 할 경우가 있으니 잘 알아두어야 한다. (어떤 요약된 정보를 데이터프레임으로 넣어서 만들어야 할 때가 있다.)
- 데이터
- 열 이름(데이터프레임의 자존심! 열이 여러개이므로 s를 반드시 써준다)
- 인덱스 이름(하나이므로 s 안붙인다)
1) 리스트로 만들기
여러 값을 주므로 리스트로 묶어서 전달해준다. (데이터, 인덱스, 열 이름 등 전부!)
# 라이브러리 불러오기
import pandas as pd
# 리스트 만들기 + 인덱스 지정 + 열 이름 지정
stock = [[94500, 92100, 92200, 92300],
[96500, 93200, 95900, 94300],
[93400, 91900, 93400, 92100],
[94200, 92100, 94100, 92400],
[94500, 92500, 94300, 92600]]
dates = ['2019-02-15', '2019-02-16', '2019-02-17', '2019-02-18', '2019-02-19']
names = ['High', 'Low', 'Open', 'Close']
# 데이터프레임 만들기
df = pd.DataFrame(stock, index=dates, columns=names)
# df = pd.DataFrame(data=stock) # 매개변수가 처음 것이니까 생략해도 자동으로 적용된다.
# 확인
df.head()
2) 딕셔너리로 만들기
딕셔너리의 key가 열 이름이 된다. 데이터프레임의 자존심은 컬럼이고, 딕셔너리의 자존심은 키이다.
# 딕셔너리 만들기
cust = {'Name': ['Gildong', 'Sarang', 'Jiemae', 'Yeoin'],
'Level': ['Gold', 'Bronze', 'Silver', 'Gold'],
'Score': [56000, 23000, 44000, 52000]}
# 데이터프레임 만들기
df = pd.DataFrame(cust, index=['C01', 'C02', 'C03', 'C04'])
# 확인
df.head()
CSV 파일 읽어오기
- sep: 구분자 지정(기본값 = 콤마)
- header: 헤더가 될 행 번호 지정(기본값 = 0)
- index_col: 인덱스 열 지정(기본값 = False)
- names: 열 이름으로 사용할 문자열 리스트
- encoding: 인코딩 방식을 지정
참고
한글이 포함된 파일을 읽을 때 다음과 같은 encoding 오류가 발생하면 encoding='CP949'로 지정
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb1 in position 0: invalid start byte
# 데이터 읽어오기
path = 'https://주소.csv' # 로컬 데이터는? path = 'tips.csv'
weather_simple = pd.read_csv(path)
# 상위 5개 확인
weather_simple.head()인덱스 다시 설정
1) 일반 열을 인덱스로 지정
- 파일 불러올 시 인덱스가 될 열을 선택: index_col 옵션
- 파일을 불러온 후 인덱스가 될 열을 설정: set_index()
# 아예 불러올 때 컬럼을 인덱스로 설정해서 불러와줄 수 있다.
weather_simple = pd.read_csv(path, index_col='month')
# 불러온 후에도 인덱스로 만들 열을 설정해줄 수 있다.
pop = pop.set_index('year') # pop.set_index('month', inplace=True)참고
set_index는 데이터프레임을 건드리는 것인데, 원본에 반영을 하지는 못하고, index가 되었을 때의 결과만 반환해준다. 사실, 데이터프레임을 변경하는 메소드는 기본적으로 원본 데이터프레임을 변경하지 못한다. 그래서 변수로 받아주거나 inplace=True를 적용해주어야 한다.

# 반환을 하는 것이니 이런 것도 가능하다.
pop.set_index('month', inplace=True).head().plot()2) 인덱스 이름 삭제
인덱스 이름을 특별히 사용할 일이 없어서 삭제해도 된다. (이름 때문에 공간이 떨어져 보여서 가독성이 떨어지는 것도 있다. 왕년에 뭐였는지 중요하지 않다.
# 인덱스 이름 삭제
pop.index.name = None
3) 인덱스 초기화
reset_index() 메서드로 초기화가 가능하다. drop=True로 설정하면 기존 인덱스 열을 일반 열로 가져오지 않고 버리게 된다.
# 인덱스 초기화
pop.reset_index(drop=False) # drop=False, inplace=True하면 원본 데이터가 변한다.4) 기존 인덱스 이름 변경하기
# 인덱스 이름 변경: index --> month
temp.rename(columns={'index':'year'}, inplace=True)
데이터프레임 탐색
탐색은 이제 데이터프레임의 키와 몸무게를 재보는 것이라고 할 수 있다. 데이터프레임으로 불러온 데이터의 크기, 내용, 분포, 누락된 값 등을 확인해보고, 이를 통해 데이터 전처리가 어디가 필요할지 결정하게 된다. 예쁘게 전처리하기 위해서는 먼저 데이터를 이해해야 한다. 데이터를 전체를 샅샅이 살피기보다는 몇 건일까? 전체 행 수는 어떻게 될까? 이런 것들을 살펴보는 것이다. 병원에 의사가 가면 먼저 살펴보고, 키와 몸무게부터 재본다. 이런 것들을 탐색이라고 한다. 인간의 대한 이해를 통해 인간을 치료하듯. 분석을 위해 전처리를 해야 하는데, 그 전처리를 위해 탐색이라는 과정은 필수이다.
익숙해져야 할 속성과 메소드 목록
- head(): 상위 데이터 확인
- tail(): 하위 데이터 확인
- shape: 데이터프레임 크기
- index: 인덱스 정보 확인
- values: 값 정보 확인
- columns: 열 정보 확인
- dtypes: 열 자료형 확인
- info(): 열에 대한 상세한 정보 확인
- describe(): 기술통계정보 확인
행, 열, 값 확인하기
# 행 확인 # 인덱스 확인
tip.index # RangeIndex(start=0, stop=244, step=1)
# 열 확인
tip.columns # Index(['total_bill', 'tip', 'sex', 'smoker', 'day', 'time', 'size'], dtype='object')# tip 데이터프레임의 values를 배열 형태로 나타내라!
# 값 확인 # 데이터프레임에서 values를 확인하면 그 값은 배열로 나타남
tip.values
# array([[16.99, 1.01, 'Female', ..., 'Sun', 'Dinner', 2],
# [10.34, 1.66, 'Male', ..., 'Sun', 'Dinner', 3],
# [21.01, 3.5, 'Male', ..., 'Sun', 'Dinner', 3],
# ...,
# [22.67, 2.0, 'Male', ..., 'Sat', 'Dinner', 2],
# [17.82, 1.75, 'Male', ..., 'Sat', 'Dinner', 2],
# [18.78, 3.0, 'Female', ..., 'Thur', 'Dinner', 2]], dtype=object)
칼럼 이름만 리스트에 담아 조회하기
col_names = list(titanic)
col_names # ['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'Fare', 'Embarked']정렬해서 보기: sort_values(ascending=False)
특정 열을 기준으로 정렬하는 방법이며, 기본값은 오름차순(ascending=True)이다. 따라서 내림차순 해주기 위해서는 ascending=False로 변경해주어야 한다.
활용 예
# 이것만 가져와서 시각화하고 싶으면
temp_top5 = temp.sort_values("min_temp").head(10).reset_index(drop=True).plot()
temp_top5
복합 열 정렬
# 복합 열('total_bill', 'tip') 정렬
# tip.sort_values('total_bill', 'tip', ascending=False) --> 오류
# 앞에는 한 개만 와야 해서 리스트 형태로 묶어서 줘야 한다.
tip.sort_values(['total_bill', 'tip'], ascending=False)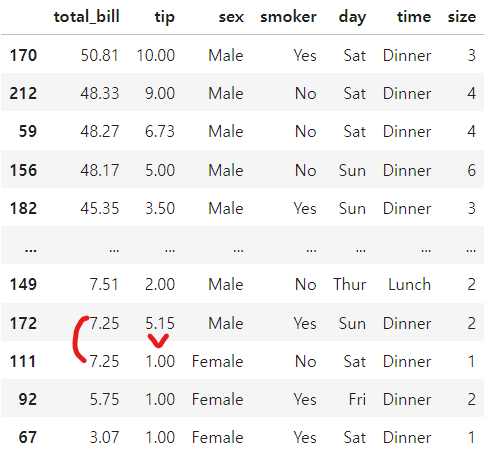
# 만약 앞은 내림차순, 뒤는 오름차순 하고 싶다면?
tip.sort_values(['total_bill', 'tip'], ascending=[False, True])기본 집계
고윳값 확인
# day 열 고윳값 확인
tip['day'].unique() # 4개가 유니크한 값이고, 고유한 값이고, 다 문자형이다.
# array(['Sun', 'Sat', 'Thur', 'Fri'], dtype=object)
# unique()는 series 자료형일 때 적용됨# 특정 열의 고윳값 개수 확인 # day 열 고윳값 개수 확인
tip['day'].value_counts()
# day
# Sat 87
# Sun 76
# Thur 62
# Fri 19
# Name: count, dtype: int64
# dropna 옵션을 생략하거나 dropna=True로 지정하면 NaN 값은 대상에서 제외# 비율로 알고 싶을 때
tip['smoker'].value_counts(normalize=True)
# smoker
# No 0.618852
# Yes 0.381148
# Name: proportion, dtype: float64
# 위와 같은 방법이다.
tip['smoker'].value_counts() / len(tip)
# day 열 고윳값 개수 확인
tip['day'].value_counts().plot(kind='bar')
최빈값 확인
# day 열 최빈값 확인
tip['day'].mode()
# 0 Sat
# Name: day, dtype: object
# 최빈값만 얻기 # 0번 index를 조회하면 된다.
tip['day'].mode()[0] # 'Sat'전체 열, 행 기준 합
- 모든 열을 더하라: df.sum(axis=1) --> 인덱스별(시계열이면 날짜별) 합
- 모든 행을 더하라: df.sum(axis=0) --> 각 컬럼별 합
- 모든 열을 더하지만 숫자 열에 대해서만 더하라: df.sum(numeric_only=True)
컬럼 지정 합계, 최댓값, 평균값
- 컬럼 지정 합계 구하라: df['total_bill'].sum()
- 컬럼 지정 최댓값 구하라: df['total_bill'].max()
- 컬럼 지정 평균 구하라: df[['total_bill', 'tip']].mean()
- 컬럼 지정 중앙값 구하라: df[['total_bill', 'tip']].median()
데이터프레임 조회
특정 열 조회: df.loc[행, 열]
- 특정 열과 모든 행 조회: tip.loc[:, 'total_bill'] or tip[['total_bill']]
- 두개의 열 조회: tip[['tip', 'total_bill']]
# tip, day, time 열만 tip 열 기준으로 내림차순 정렬해서 10개 행만 조회
tip.loc[:, ['tip', 'day', 'time']].sort_values(by='tip', ascending=False).head(10)
# 10개 조회면 꼭 안에 10을 넣어줘야한다! 자꾸 까먹는다! ㅠㅠ
tip.loc[:, ['tip', 'day', 'time']].sort_values(by='tip', ascending=False)[:10]
열 범위 조회: df.loc[:, 열 이름1:열 이름2]
- tip.loc[:, 'sex':'time'] --> sex열부터 time열까지 포함하여 조회
- ☆주의☆ 범위 마지막 열도 조회 대상에 포함(인간적인 조회 방법이라..!)
- ☆주의☆ 범위 검색은 생략할 수 없다.
조건으로 조회: df.loc[조건]
- 단일 조건 조회(ex. tip 열 값이 6.0 보다 큰 행 조회): tip.loc[tip['tip'] > 6.0, :] or tip.loc[tip['tip'] > 6.0]
- 여러 조건 조회: tip.loc[(tip['tip'] > 6.0) | (tip['day'] == 'Sat')]
- 값1 또는 값2 또는...값n인 데이터만 조회(ex. day가 Sat 또는 Sun이면 데려오기): tip.loc[tip['day'].isin(['Sat', 'Sun'])]
- 칼럼의 값이 x에서 y 사이의 데이터만을 조회(ex. 1 <= size <= 3): tip.loc[tip['size'].between(1, 3)]
- 조건을 만족하는 행의 일부 열 조회: df.loc[조건, ['열 이름1', '열 이름2',...]] --> tip.loc[tip['size'] >= 5, ['total_bill', 'tip']]
변수.loc를 이어나가기 때문에 이미 변수를 지정했음에도 loc안에 변수['열이름'] 써야하는 이유? (sort_value나 groupby는 안에 '칼럼명'만 쓰는데..)
tip.loc[tip['tip'] > 6.0]
- 안에 칼럼의 이름은 꼭 써줘야 한다. 안에 있을지라도. 왜냐하면 이 조건에 다른 데이터프레임의 칼럼 가지고도 조건을 줄 수 있나? 나중에는 그게 가능하다. 즉, 조건문에 타 df의 칼럼을 가지고 조건문을 구성할 수도 있다. 그래서 반드시 어떤 데이터프레임의 어떤 칼럼이야. 라는 것을 줘야 한다. 다른 sort_value는 반드시 .앞에 써준 데이터프레임의 칼럼만 가지고 한다. 라는 것을 이미 상정하고 쓰는 것이기 때문에 굳이 써주지 않는다.
조건을 만족하는 행의 일부 열 조회할 때, 왜 조건 쪽에는 df명을 써주고, 조회하는 열 쪽에는 안 써주나?
titanic.loc[titanic['Sex'] == 'male', 'Age']
- (개인 생각) ,앞은 조건을 걸어주는 쪽이어서 위와 같은 논리가 적용된다. 그런데 조건이 아닌 기본적인 열 조회, 행 조회는 우리가 그냥 '칼럼명'으로만 넣어줬었다. 그래서 그와 같은 논리로 조회하는 열 쪽에는 df명을 적어주지 않고 '칼럼명'만 적어주는 것으로 이해해보자.
between은 왜 ( )이고, isin은 왜 ([ ])로 넣어주나?
between은 값을 지정해서 넣어주면 된다. 10에서 20이면 (10, 20). 딱 두 개 값만 요구가 된다. 그래서 굳이 대괄호가 필요하지 않다. 그러나 isin은 혹시 이런 애들 있어? 하는 것이니 이게 몇 개가 나올 지를 모른다. 여러 개를 받아줘야 할 수도 있다. 그래서 여러 개를 받을 수 있는 자료형인 리스트를 안에 넣어준다. 몇 개가 들어올 줄 모르면 그냥 리스트로 다 받아준다고 생각해보자.
# 오존 농도 10~20 사이의 데이터를 조회하시오.
air.loc[air['Ozone'].between(10, 20)]
# 날짜(Date) 1973-05-01, 1973-06-01, 1973-07-01 , 1973-08-01 을 조회하시오.
air.loc[air['Date'].isin(['1973-05-01', '1973-06-01', '1973-07-01', '1973-08-01'])]between으로 초과/미만.. 이런 것들을 지정해줄 수는 없나?
있다! 오른쪽에만 <=을 붙이고 왼쪽은 <만 해주고 싶다면 inclusive='right'를 써주면 된다. 반대의 경우는 'left'를 써주자. 예시는 아래와 같다.
# 초과/미만 할 때
air.loc[air['Ozone'].between(10, 20)] # 10<=, <=20
air.loc[air['Ozone'].between(10, 20, inclusive='right')] # 오른쪽에만 =을 붙여. # 10<, <=20데이터프레임 집계
- day별 tip 합계: tip.groupby(by='day', as_index=False)[['tip']].sum()
- day, sex별 나머지 모든 열 평균: tip.groupby(by=['day', 'sex'], as_index=False).mean(numeric_only=True) # mean은 이부분 안써주면 큰일
'데이터 분석 > Pandas 기초' 카테고리의 다른 글
| 데이터프레임 변경(4): Rolling과 Shift / Pivot과 Melt (2) | 2024.09.26 |
|---|---|
| 데이터프레임 변경(3): 합치기(Concat)와 조인(Merge) (2) | 2024.09.25 |
| 데이터프레임 변경(2): 결측치 처리 / 가변수(Dummy Variable) 생성 (0) | 2024.09.25 |
| 데이터프레임 변경(1): 열(이름변경, 추가, 삭제) / 범주값(변경, 생성) (2) | 2024.09.24 |
| 넘파이 배열의 기본 개념 (1) | 2024.09.21 |