1. 열 이름 변경
1) 일부 열 이름 변경: rename()
전체 열 중에 1, 2개를 바꾼다면 이 방법을 사용하는 것이 좋다. 그러나 전체 열 이름 바꿀 경우 비효율적
# rename() 함수로 열 이름 변경 # 여러 개를 바꾸니 딕셔너리를 쓰면 좋겠다.
tip.rename(columns={'total_bill_amount': 'total_bill',
'male_female': 'sex',
'smoke_yes_no': 'smoker',
'dinner_lunch': 'time'}, inplace=True)
2) 모든 열 이름 변경: columns 속성
전체 열 이름 바꿀 경우 그냥 덮어씌워주면 된다.
# 모든 열 이름 변경:
# ['total_bill', 'tip', 'sex', 'smoker', 'day', 'time', 'size']
tip.columns = ['total_bill', 'tip', 'sex', 'smoker', 'day', 'time', 'size']
# 7개 열 중에서 5개를 바꾸는데, 안바뀐 2개는 그냥 써준다.
2. 열 추가
의미있는 데이터를 만들기 위해서 전처리를 하는 것인데, 그 중에 대표적인 것이 '열 추가'이다. 의미 있는 열을 추가해야 한다. 이런 것을 컬럼 공학, feature engineering이라고 한다. 결국 좋은 데이터를 갖고 있는 사람이 좋은 결과를 얻는 법이다.
열 추가의 경우, 이를테면 나이가 있지만 그것을 필요하다면 구간을 주어 추가할 수도 있다. 또 둘을 더한 것도 의미가 있다. 또 그것을 인원수별로 나눌 수도 있다. 인원수당 00. 다양하게 추가해보자.
1) 기본적인 열 추가: "있으면 변경, 없으면 추가"
# final_amt 열 추가: final_amt = total_bill + tip
# tip['size'] = 10 # 있는 열이면 다 10으로 값이 바뀌어버리니 주의
tip['final_amt'] = tip['total_bill'] + tip['tip']
2) 원하는 위치에 열 추가: insert()
이 메서드는 이전에 한 번 본 적이 있다. 리스트에서. 이 메서드를 사용하면 원하는 위치에 열을 추가할 수 있다. 리스트에서는 맨 뒤에 하나를 넣는 append()와 비교해서 중간에 넣는 것을 insert()라고 했었던 것을 기억해보자.
(그런데 사실 꼭 특정한 위치에 추가하려고 고생할 필요는 없다. 그러나 누군가 요구한다면 할 줄은 알아야 한다. 개인적으로 할 때는 원하는 순서대로 조회해서 df로 넣어주면 된다.)
# tip 열 앞에 div_tb 열 추가: div_tb = total_bill / size
# 집어넣을 게 1열이 되고 원래 1열은 2열로 밀려나게 된다.
tip.insert(1, 'div_tb', tip['total_bill'] / tip['size'])
3) 응용편 열 추가: isin()
isin()은 데이터프레임의 조건 조회에서 봤었는데, 값이 x면 a, 값이 y면 b로 바꾸어주는 열을 새로 추가해볼 때도 사용해볼 수 있다. 아래의 문제를 참고해보자.
# day가 Sat, Sun 이면 1, 나머지는 0 값을 갖는 holiday 열을 추가하세요.
# holiday 열 추가
tip['holiday'] = 0 # 없으면 추가
# 조건 주어서
tip.loc[tip['day'].isin(['Sat', 'Sun']), 'holiday'] = 1
# tip.loc[(tip['day'] == 'Sat' )| (tip['day'] == 'Sun'), 'holiday'] = 1
# 확인
tip['holiday'].value_counts()
# holiday
# 1 163
# 0 81
# Name: count, dtype: int64
3. 열 삭제
1) 열 하나 삭제: drop()
drop() 함수는 여러 열을 한 번에 삭제할 수 있도록 설계되었기 때문에, 항상 열 이름을 리스트로 제공해야 한다.
- 한편, 모든 전처리 과정에 대해서 명확하고 구체적인 자신만의 이유가 있어야 한다. 그냥, 이라고는 할 수 없다.
(ex. holiday를 만들었으니 day는 지워도 될 것이라고 판단)
# 열 하나 삭제
drop_cols = ['final_amt']
tip.drop(columns=drop_cols, inplace=True)
# 열 여러 개 삭제
drop_cols = ['div_tb', 'day']
tip.drop(columns=drop_cols, inplace=True)
4. 범주값 변경
1) 범주형 값을 다른 값으로 변경(1) : map()
범주값이 대부분 str인데, 이를 컴퓨터에게 줄 때 숫자형으로 바꿔야 할 때가 있다.
가령, male은 1로 바꾸고, female은 2로 바꾸라고 할 수 있다. 만약 이렇게 지정이 안 된 범주형 값들이 있다면? 자동 결측치 처리가 된다. (이를 의도할 수도 있지만, 대체로 누락값이 없도록 쌍을 주자. 결측치 나온 값들을 지워줄 예정인 경우는 이렇게 처리 가능)
# Male -> 1, Female -> 0
tip['sex'] = tip['sex'].map({'Male': 1, 'Female': 0})
사용시, 앞서 확인해보는 습관 들이기!
map()은 여러 번 돌리면 안 되는 작업이다. 그래서 먼저 확인해봐야 한다. ( 코딩은 겸손해야 한다. )
즉, sex가 0과 1로 정확히 바뀌었는지 확인해야 한다.먼저 받아주기 전에 tip['sex'].map({'Male': 1, 'Female': 0})만 출력해서 확인해보자.
inplace 매개변수 지정할까? 열로 받을까?
데이터프레임 자체에 대한 변경은 inplace가 필요하지만, 데이터프레임의 특정 열에 대한 변경은 inplace보다는 바로 열이 받아줄 수 있도록 하는 것을 극 권장한다!
2) 범주형 값을 다른 값으로 변경(2): replace()
map()과 비슷한 방식으로 사용 가능하나, map()과 달리, 지정이 안 된 범주형 값들이 있다면?
해당 값('c')는 그대로 'c'인 채로 남는다.
또한, map()과 달리, replace()는 여러 번 돌릴 수 있다는 점도 차이이다.
# 1 --> Male, 0 --> Female
# tip['sex'].replace({1: 'Male', 0: 'Female'})
tip['sex'] = tip['sex'].replace({1: 'Male', 0: 'Female'})
5. 범주값 생성
연속값을 구간을 나눠서 범주값으로 표현해야 할 때가 있는데, 이 과정을 이산화(Discretization)라고 한다.
연속값을 이산화하면 더 심도있는 데이터 분석이 가능해진다. 동일한 가지고 있는 데이터를 가지고 통찰은 다 다를 수 있다. 가령, 점수를 일정 구간으로 구분하게 된다면 점수 구간별 분석이 가능해질 수 있으며, 기존에 보지 못했던 것들을 발견할 수도 있게 될 것이다.
이런 것들을 가능하게 하기 위해서 데이터를 계속 탐색한다고 볼 수 있다. 의미있는 열을 추가하기 위해서. 의미있는 열을 추가한다면, 이후 의미있는 예측도 할 수 있게 된다.
사용방법은 다소 복잡하지만, 알아두면 상당히 유용하고 편리한 기능이므로 잘 적응해두자!
1) 데이터 분포에 따라 자동 구간 나누기: qcut()
데이터의 개수에 따라 각 구간에 동일한 수의 값이 들어가도록 자동으로 조절하고 싶을 때, 이 방법을 사용하면 된다.
값의 크기가 어떤지는 중요하지 않고, 비율에 따라 자동으로 구간이 정해진다. 쉽게 생각하면, 데이터의 분포에 따라 자동으로 구간을 나눠준다고 생각하면 된다. 그러면 각 구간에 들어가는 데이터 개수는 같아진다. quantity cut이라고 하는데, 그냥 quick cut이라고 생각해도 좋을 것 같다.
- 데이터가 너무 많을 때, 2로 지정해주면 알아서 절반으로 들어간다.
- 만약 4개 구간으로 설정해준다면, 사분위수로 나눠지게 할 수도 있다. (이때, 중앙의 값은 중앙값이 되고, 양 옆은 25%, 75% 값이 될 것이다)
# 같은 개수의 total_bill을 갖는 4개 구간으로 나누기
tip['bill_grp2'] = pd.qcut(tip['total_bill'], 4, labels=list('abcd')) # list('abcd'): ['a', 'b', 'c', 'd']
2) 고정된 절대적 기준에 따라 데이터를 구간으로 나누기: cut()
보통, 회사에서 구간의 값을 나누는 기준이 있는 경우 이 방법을 사용한다. 이를테면 백화점에서 고객 등급을 나누려고 하는데, 몇부터 몇까지를 플래티넘으로 할까? 이는 백화점에서 정할 것이다. 이처럼 cut을 사용할 때는 경계를 어떻게 할지 잘 설정해야 하며, 그 값을 정할 타당한 근거를 제시해주어야 한다.
cut은 경계값을 써서 기준으로 나누기 때문에 각 구간 안에 들어갈 데이터 수는 예측이 불가능하다.
- 한편, 음의 무한대는 -np.inf, 양의 무한대는 np.inf로 지정해준다. (맨 첫 구간으로 0을 적었을 때, '0초과'의 의미기에 0이 포함이 안되는 문제가 발생한다. 그래서 맨 첫 구간은 반드시 -np.inf로 적어주자. 혹은 최솟값에서 -1을 해줘도 된다.)
# tip 크기를 기준으로 4구간(a ~ d)으로 나누기
tip['tip_grp'] = pd.cut(tip['tip'], 4, labels=['a', 'b', 'c', 'd'])
# 동일: tip['tip_grp'] = pd.cut(tip['tip'], 4, labels=list('abcd'))# 앞선 qcut과 동일한 값을 얻도록 하는 cut 구문 짜기
# 사분위수
q1 = tip['total_bill'].describe()['25%']
q2 = tip['total_bill'].describe()['50%']
q3 = tip['total_bill'].describe()['75%']
# 등급 구하기
bin = [-np.inf, q1, q2, q3, np.inf]
label = ['a', 'b', 'c', 'd']
tip['bill_grp'] = pd.cut(tip['total_bill'], bins=bin, labels=label)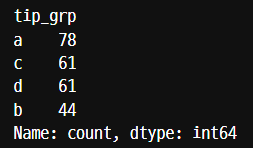
4분위수로 나눠줬는데, 왜 각 구간별 개수가 동일하지 않은가?
4분위수로 맞춰서 경계값을 넣어주었기 때문에, (원래 cut은 그렇지 않지만,) 데이터 개수가 구간별로 동일해야 할 것 같다.그러나 동일하지 않다. 이는 경계값에 동일값이 존재하는 경우, 경계값과 똑같은 값은 왼쪽 구간으로 들어가기 때문이다.대개 데이터가 많으면 많을수록, 거의 각 구간이 균일한 개수가 된다.
'데이터 분석 > Pandas 기초' 카테고리의 다른 글
| 데이터프레임 변경(4): Rolling과 Shift / Pivot과 Melt (2) | 2024.09.26 |
|---|---|
| 데이터프레임 변경(3): 합치기(Concat)와 조인(Merge) (2) | 2024.09.25 |
| 데이터프레임 변경(2): 결측치 처리 / 가변수(Dummy Variable) 생성 (0) | 2024.09.25 |
| 데이터프레임 생성, 탐색, 조회, 집계 (2) | 2024.09.23 |
| 넘파이 배열의 기본 개념 (1) | 2024.09.21 |