1. 데이터프레임 합치기: Concat()
예를 들어 한 회사의 구성원들의 휴가 정보 테이블이 있다고 해보자. 이 테이블이 너무 커서, 파일을 3개로 잘라내서 나에게 도착했다. 1번 파일은 2024년 휴가 정보, 2번 파일은 2023년 휴가 정보, 3번 파일은 2022년 휴가 정보라고 해보자. 이 3개의 파일을 하나로 붙여서 통합된 데이터로 만들고 싶을 수 있다.
우리는 지금까지 하나의 데이터프레임을 가지고 작업을 해왔기 때문에, 그 형태로 맞춰주는 것이 좋겠다. 이때 concat() 함수를 사용해서 인덱스 값을 기준으로 두 데이터프레임을 가로 혹은 세로로 합칠 수 있으며, 이를 '연결'이라고 한다. 테이블이 가로로 분리되어 있다면 가로로 다시 연결해주고, 세로로 분리되어 있다면 세로로 다시 연결해주는 것이다.
1) 가로로 합치기
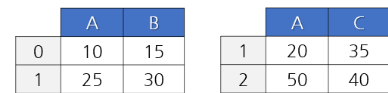
concat()은 인덱스를 가지고 연결해주는 애이다. 그래서 연결할 두 데이터프레임의 인덱스 칼럼을 이를 염두해 두고 설정해주는 것이 좋다. 가로로 합칠 때에는 axis=1 옵션을 지정해서 아래와 같이 합쳐줄 수 있다.
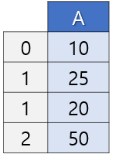
한편, concat()은 한 번에 두 개씩밖에 할 수 없으므로 3개의 데이터프레임을 합치려면 2번 concat을 해주어야 한다. concat()에 두 데이터프레임을 적을 때에는, 여러 개를 넣게 되니 리스트로 묶어주고, join 방식(기본값: join='outer')과 축 옵션(기본값: axis=0)을 지정해준다.
# 첫번째 데이터프레임 불러오기
pop01 = pd.read_csv(path, index_col='year')
pop01.index.name = None
# 두번째 데이터프레임 불러오기
pop02 = pd.read_csv(path, index_col='year')
pop02.index.name = None
# 모든 열 합치기
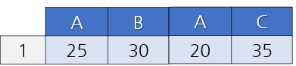
pop = pd.concat([pop01, pop02], join='outer', axis=1) # 가로로 붙이는 것이니 axis=1이라고 한다.
pop = pd.concat(['pop01', 'pop02']) → 이렇게 ' '를 적지 않는 이유?
' '를 넣으면 문자열이다. 컬럼 등을 가리킬 때 그렇게 한다. 문자열이 아니다. 데이터프레임을 품고 있는 것이다. 데이터프레임이 리스트 멤버가 되기에, pop01, pop02와 같이 변수로 그대로 넣어주어야 한다.
헷갈리지 않기! join과 how
concat에서는 join이라고 하고, join에서는 how라고 한다. 이 부분 많이 헷갈리니 꼭 기억해두자.
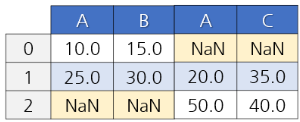
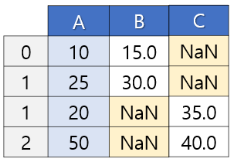
왜 outer 방식에서는 실수형으로 변한걸까?
NaN 값이 있으면 결측치 자료형은 float가 나와서 이를 반영한 것이다. 예쁜 데이터를 만들기 위해서는 astype(int)를 해주면 좋겠다.
inner로 하면 결측치가 없나? 아니다!
원래 데이터프레임 자체에 결측치가 있을 수도 있다. inner 방식으로 연결했을 때에는 서로 매핑되지 못해서 발생하는 결측치만 없는 것이다. outer 방식은 매칭되지 않는 것들도 포함시켜서 결측치가 더 생기는 방식인 것이라고 이해하자.
2) 세로로 합치기
axis=0 옵션을 지정해 세로로 합칠 수 있다. axis=0이 기본값이기에 이는 생략해줄 수도 있다.
# 모든 행 합치기
pop = pd.concat([pop01, pop02], join='inner', axis=0) # axis=0 디폴트라 생략해도 좋다.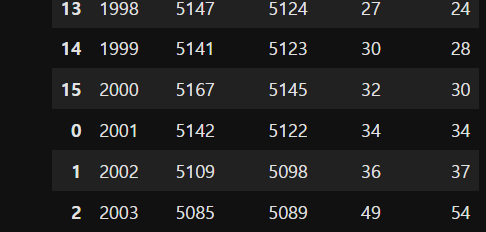
# 인덱스 초기화
pop.reset_index(drop=True, inplace=True)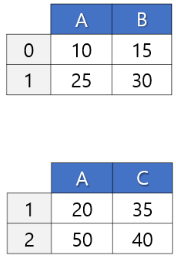
2. 데이터프레임 조인: Merge()
merge()는 데이터 전처리 과정 중에서 제일 어려운 과정이라고도 이야기되기도 한다. 그러나 필수적이라 이를 못하면 분석 자체를 할 수 없게 되는 상황도 온다고 한다.
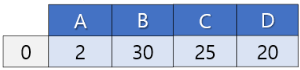
어떤 상황에서 필요할까? 이를테면 직원 정보가 있는 Employee 데이터프레임이 있다고 하자. 여기에는 부서코드로 sys, mkt 등이 있다. 그러나 이 알파벳만 봐서는 부서 이름을 알 수가 없다. 부서 이름을 같이 표시해주고 싶은데? 그런데, 알고보니 부서 테이블이 따로 있다. Department 테이블이 따로 있다. 이 데이터프레임에서는 sys, mkt 이런 값들이 인덱스 열 아래에 있고, 정보처리부 이런 식으로 다른 열에 부서 설명이 입력되어 있다. 이를 가져와주면 좋겠다. 이때 필요한 과정이라고 보면 된다.
merge() 함수를 사용하면 두 데이터프레임을 지정한 키 값을 기준으로 병합할 수 있다. merge()의 경우 방법이 3가지로, inner, outer 외에도 left, right도 있다. 위아래로는 보통 concat()으로 많이 처리하지만, merge로는 93.3%로 가로로 붙이게 된다. 보통 다른 데에서 컬럼을 가져올 때 쓰는 것이기 때문에 그렇다. (그래서 그런지 merge()의 인수로는 axis도 존재하지 않는다.)
네 가지 방식에 대하여: like ' 교집합, 합집합, 여집합...'
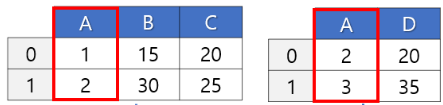
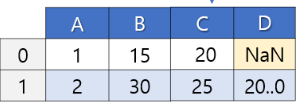
- INNER: 이건 비교하려는 게 같은 것끼리면 가져오겠어. (연도라고 하면 같은 연도만.)
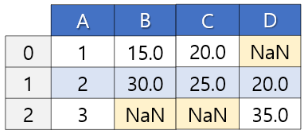
- OUTER: 양쪽 것 다 가져오겠어. (데이터 유실은 없는데 결측치가 생길 가능성이 많다.)
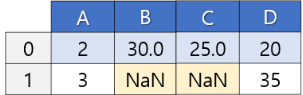
- LEFT: 왼쪽만 가져오겠어. (교집합도 포함해서 왼쪽 것 다 가져오겠어.)
- RIGHT: 오른쪽만 가져오겠어. (교집합도 포함해서 오른쪽 것 다 가져오겠어.)
1) inner 조인
같은 이름의 열이 있으면 on 옵션을 지정하지 않아도 그 열을 기준으로 조인해준다. 그래도 기준 열을 명시적으로 지정하는 것이 권고되므로 되도록이면 지정해주자. how='inner' 옵션이 기본값이므로 이는 생략이 가능하다.
# 조인
pop = pd.merge(pop01, pop02, how='inner', on='year')
2) outer 조인
outer 조인의 경우, how='outer' 옵션을 지정해서 조인해준다.
# 조인
pop = pd.merge(pop01, pop02, how='outer', on='year')'데이터 분석 > Pandas 기초' 카테고리의 다른 글
| 데이터프레임 변경(4): Rolling과 Shift / Pivot과 Melt (0) | 2024.09.26 |
|---|---|
| 데이터프레임 변경(2): 결측치 처리 / 가변수(Dummy Variable) 생성 (0) | 2024.09.25 |
| 데이터프레임 변경(1): 열(이름변경, 추가, 삭제) / 범주값(변경, 생성) (0) | 2024.09.24 |
| 데이터프레임 생성, 탐색, 조회, 집계 (1) | 2024.09.23 |
| 넘파이 배열의 기본 개념 (1) | 2024.09.21 |