
1. Rolling
rolling() 메서드를 사용하면 일정 기간에 대한 집계를 수행할 수 있다. 예를 들어 최근 3일간 혹은 일주일 간의 평균이나 합을 집계 가능하다. 우선 일상적으로 우리가 하는 집계부터 살펴보자.
1) 일상적인 집계
일상적으로는 특정 열의 평균이나 합 등과 같은 집계를 수행한다. 전체 평균을 이런 식으로 집계해서 새로운 열로 만들어주면, 이후에 전체 평균 대비 오존 농도 평균이 얼마인지에 대해 시각화해볼 수도 있다.
# 새로운 열 추가
air['OZ_mean'] = round(air['Ozone'].mean(), 1)
2) Rolling 집계
시계열 데이터의 경우, 최근 일정 기간에 대한 집계가 필요할 수 있다.
이때 rolling() 메서드를 적용하게 되는데, 특정 창(window)을 기준으로 이동 평균, 이동 합계 등과 같은 집계 작업을 수행한다.
지정해줘야 하는 매개변수
- window 매개변수에 대한 대상 행 수를 지정: 매개변수 이름 생략 가능
- min_periods 매개변수에 몇 개의 행만 있어도 집계를 수행할지 지정
# 최근 3일간 Ozone 열 평균
air['Ozone'].rolling(3).mean()
테이블이 있는데, 위 세 개 행의 평균을 출력하고 있는 것이기에 0번 행과 1번 행은 값이 없는 것이다. 만약 이것들도 값을 채워주고 싶다면, min_periods=1로 해서 3개가 아니라 값이 하나만 있어도 평균을 내게 해라. 하고 재정해줄 수 있다. 단위를 뭘로 볼 것인지는 window로 지정해준다.
# 최근 3일간 Ozone 열 평균
air['Ozone'].rolling(window=3, min_periods=1).mean()
# 최근 7일간 Ozone 열 평균
air['Ozone'].rolling(window=7, min_periods=1).mean()이런 집계 결과를 새로운 열로 추가해 분석에 활용할 수 있다. 예를 들어 당일 Ozone 열 값을 최근 3일 또는 7일간의 평균과 비교할 수 있다.
# 새로운 열 추가
air['OZ_mean_3'] = round(air['Ozone'].rolling(window=3, min_periods=1).mean(), 1)
air['OZ_mean_7'] = round(air['Ozone'].rolling(window=7, min_periods=1).mean(), 1)
최근 3일의 평균과 7일의 평균은 오존 농도를 예측하는데 도움이 될까 안될까?
도움이 엄청 된다. 시계열 데이터 예측할 경우, 전처리 과정에서 이런 추가적인 열들을 더 많이 만들어낼 수 있다.
전날 오존농도, 전전날 오존농도가 있으면 내일의 오존농도를 예측하는 데 중요한 의미를 가진다. 이런 것들을 담는 추가적인 열을 만들어내는 것을 피처 엔지니어링이라고 한다. 전처리에 들어가는 아주 고급 기술이라고 할 수 있다.
2. Shift
데이터를 행 방향 또는 열 방향으로 이동시킬 때 shift() 메서드를 사용한다. 이 메서드는 데이터를 특정 행이나 열 방향으로 이동시켜, 시계열 데이터에서 이전 값과 비교하는 데 사용한다.
# 새로운 열 추가
air['OZ_lag_1'] = air['Ozone'].shift(1)
air['OZ_lag_2'] = air['Ozone'].shift(2)
air['OZ_lag_3'] = air['Ozone'].shift(3)결과 해석
- shift의 결과 OZ_lag_1, 2, 3이 있다. (보통 lag는 이전 데이터를 얘기하고, lead는 나중 데이터를 가리킨다.)
- OZ_lag_1에서 41.0은 어제의 오존 농도를 가져온 것이다.
- OZ_lag_2는 그제의 오존 농도이다.
- 인덱스 4의 입장에서 보자. OZ_lag_1에서 18.0은 어제의 오존농도이다. 12.0은 그제의 오존농도이다. 36.0 이건 그제의 오존농도이다.
- 이것을 가지고 내일의 오존농도를 예측할 때 큰 역할을 할 수 있지 않을까?
- 이후 데이터 분석 단계에서 과연 이런 값들이 어떤 값을 설명하는 데 의미가 있나를 판별하게 되며, 의미가 없으면 그때 지워버리면 된다.
- 한편, 내일의 값을 땡겨오려고 하면, `shift(-1)`이라고 하면 된다.
3. Rolling & Shift
rolling(), shift() 메서드를 같이 사용할 수도 있는데, 일반적으로 당일을 제외한 기간에 대한 rolling을 수행할 때 사용한다.
다음 구문은 당일을 제외한 최근 3일간의 Ozone 값 평균을 갖는 열을 추가하는 구문이다.
# 새로운 열 추가
air['OZ_mean_3_lag_1'] = round(air['Ozone'].rolling(3, min_periods=1).mean().shift(1), 2)
OZ_mean_3은 오늘을 포함해서 최근 3일의 오존 평균이다. 그런데, 어제부터 포함해서 그제 그그제를 포함한 3일 평균을 옆에 추가하고 싶다면?
- OZ_mean_3에서 바로 위의 값을 옆의 열로 추가하면 된다.
- 즉, rolling한 것을 shift하면 되는 것이다. 이게 맨 마지막 열의 의미이다.
4. 참고: 내일의 Ozone 값을 예측하려면?
내일의 Ozone 값을 예측하는 머신러닝 모델을 만들 때는 1일 후 값을 각 행에 추가해야 한다.
즉, 당일 Ozone, Temp, Solar.R, Wind 정보와 최근 Ozone 값과 Ozone 값 평균 등을 활용해 다음 날 Ozone 값을 예측하게 할 수 있다.
# 새로운 열 추가: 다음날 Ozone 값 (예측 대상)
air['OZ_lead_1'] = air['Ozone'].shift(-1)
# 불필요한 열 제거
air.drop(['Month', 'Day'], axis=1, inplace=True)
결과 해석
- OZ_lead_1에서 0행에 있는 36.0은 내일의 오존농도이다.
- 그런데 28.0이 이 데이터프레임의 맨 마지막 행이라면? 그다음은 예측을 해야 한다. 그게 28.0인데, 이것을 맞추라고 하는 게 머신러닝이다.
- 실제 봤더니 어떻게 되었는가. 이정도면 맞췄다. 할 수도 있고. 계속 3일 뒤를 관찰하면서 수정해나갈 수 있다. 이게 바로 시계열 데이터이다.
5. Pivot
pivot() 메서드를 사용해 피벗 형태로 변경 가능하다.
# 데이터 읽어오기
bike = pd.read_csv('BikeFile.csv')
# datetime으로 바꾸기
bike['DateTime'] = pd.to_datetime(bike['DateTime'])
# Year, Month, Day, Hour 분리
bike['Year'] = bike['DateTime'].dt.year
bike['Month'] = bike['DateTime'].dt.month
bike['Day'] = bike['DateTime'].dt.day
bike['Hour'] = bike['DateTime'].dt.hour
# 데이터 선택
bike = bike.loc[:, ['Year', 'Month','Day', 'Hour', 'Count']]
# 년월일별 수요량 집계
day_count = bike.groupby(by=['Year', 'Month', 'Day'], as_index=False)[['Count']].sum()
위에서 일별이었던 것을 일(1~365)에 대해서 가로 칼럼으로 만들어버린다. 이러면 와이드하게 바꾸어서 한눈에 볼 수 있다. 이를 위해 pivot() 메서드를 사용해 위 결과 형태를 피벗 형태로 변환할 수 있다.
매개변수
- index: 움직이지 않을 열(=기준 열)
- columns: 새로운 열로 올라갈 현재 열
- values: 새로운 열의 값이 될 현재 열
# 피벗 형태로 변환
# index는 움직이지 마. 컬럼으로 올라갈 애는 day야. 그리고 count는 그 각각의 값으로 들어가라!
day_count_w = day_count.pivot(index=['Year', 'Month'], columns='Day', values='Count')
# 열 대표이름 제거('컬럼에 대한 이름이다. 나 왕년에 'day'였어! ---> 이거 지워준다. 마치 인덱스 이름 지우는 것과 같다.)
day_count_w.columns.name = None
# 인덱스 초기화
day_count_w.reset_index(drop=False, inplace=True) # 인덱스 초기화하여서 일반 열로 가라.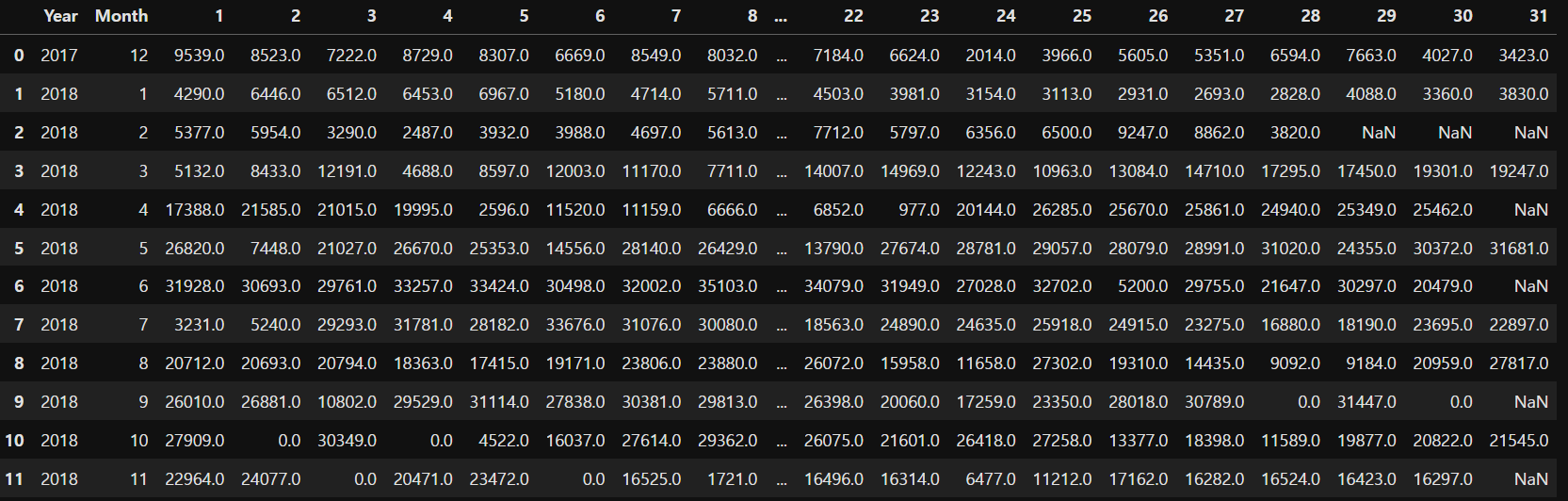
6. Melt
위의 pivot() 결과를 역으로 바꿔주는 것을 melt()라고 한다.
시각화 분석을 위해서는 이전의 형태로 돌려야 하는 경우가 많다.
매개변수
- id_vars: 움직이지 않을 열(=기준 열)
- value_vars: 값이 되어 아래로 내려올 현재 열(생략하면 id_vars에 지정한 열 이외의 모든 열)
- var_name: value_vars에 지정한 열이 값이 될 때 부여할 열 이름(생략하면 variable)
- value_name: 새로운 열이 되는 기존 값에 부여할 열 이름(생략하면 value)
# 언피벗
day_count_n = pd.melt(day_count_w,
id_vars=['Year', 'Month'],
# value_vars=range(1, 32),
var_name='Day',
value_name='Count')
# 정렬
day_count_n.sort_values(by=['Year', 'Month', 'Day'], ascending=True, inplace=True)
# 결측치 제거(31일이 꽉 차지 않는 월에 결측치 존재)
day_count_n.dropna(inplace=True)
# 인덱스 초기화
day_count_n.reset_index(drop=True, inplace=True)
# 데이터 형식 변경
day_count_n['Count'] = day_count_n['Count'].astype(int)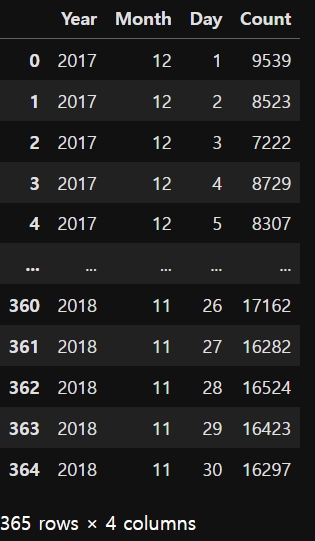
'데이터 분석 > Pandas 기초' 카테고리의 다른 글
| 데이터프레임 변경(3): 합치기(Concat)와 조인(Merge) (1) | 2024.09.25 |
|---|---|
| 데이터프레임 변경(2): 결측치 처리 / 가변수(Dummy Variable) 생성 (0) | 2024.09.25 |
| 데이터프레임 변경(1): 열(이름변경, 추가, 삭제) / 범주값(변경, 생성) (1) | 2024.09.24 |
| 데이터프레임 생성, 탐색, 조회, 집계 (2) | 2024.09.23 |
| 넘파이 배열의 기본 개념 (1) | 2024.09.21 |